K平均法 (左)および平均値シフト法(右)によるデータセットのクラスタリングの例。この2つのクラスタリングについて計算された調整ランド指数は A R I ≈ 0.94 {\displaystyle ARI\approx 0.94} ランド指数 [ 1] 英 : Rand index )またはランド測度 (ランドそくど、英 : Rand measure )は、統計 、特にデータ・クラスタリング において、2つのクラスタリングの類似性を図る尺度である。William M. Randにちなんで名付けられた。要素の偶然のグループ化を調整した形で定義したものが調整ランド指数 である。数学的には、ランド指数は accuracy に関連しているが、クラスラベルを使用しない場合にも適用できる。
n {\displaystyle n} S = { o 1 , … , o n } {\displaystyle S=\{o_{1},\ldots ,o_{n}\}} S {\displaystyle S} X = { X 1 , … , X r } {\displaystyle X=\{X_{1},\ldots ,X_{r}\}} Y = { Y 1 , … , Y s } {\displaystyle Y=\{Y_{1},\ldots ,Y_{s}\}}
a {\displaystyle a} S {\displaystyle S} X {\displaystyle X} Y {\displaystyle Y} b {\displaystyle b} S {\displaystyle S} X {\displaystyle X} Y {\displaystyle Y} c {\displaystyle c} S {\displaystyle S} X {\displaystyle X} Y {\displaystyle Y} d {\displaystyle d} S {\displaystyle S} X {\displaystyle X} Y {\displaystyle Y} ランド指数 R I {\displaystyle RI} [ 1] [ 2]
R I = a + b a + b + c + d = a + b ( n 2 ) {\displaystyle RI={\frac {a+b}{a+b+c+d}}={\frac {a+b}{n \choose 2}}} 直感的には、 a + b {\displaystyle a+b} X {\displaystyle X} Y {\displaystyle Y} c + d {\displaystyle c+d} X {\displaystyle X} Y {\displaystyle Y}
分母はペアの総数なので、ランド指数はペアの総数に対する合意の発生頻度、つまり無作為に選ばれたペアにおいて X {\displaystyle X} Y {\displaystyle Y}
( n 2 ) {\displaystyle {n \choose 2}} n ( n − 1 ) / 2 {\displaystyle n(n-1)/2}
R I = T P + T N T P + F P + F N + T N {\displaystyle RI={\frac {TP+TN}{TP+FP+FN+TN}}} ここで、 T P {\displaystyle TP} T N {\displaystyle TN} F P {\displaystyle FP} F N {\displaystyle FN}
ランド指数は0〜1の値を持ち、0は2つのデータ・クラスタリングがどのペアでも一致しないことを、1はデータクラスタリングが全く同じであることを示す。
数学的には、a、b、c、dは次のように定義される。
a = | S ∗ | {\displaystyle a=|S^{*}|} S ∗ = { ( o i , o j ) ∣ o i , o j ∈ X k , o i , o j ∈ Y l } {\displaystyle S^{*}=\{(o_{i},o_{j})\mid o_{i},o_{j}\in X_{k},o_{i},o_{j}\in Y_{l}\}} b = | S ∗ | {\displaystyle b=|S^{*}|} S ∗ = { ( o i , o j ) ∣ o i ∈ X k 1 , o j ∈ X k 2 , o i ∈ Y l 1 , o j ∈ Y l 2 } {\displaystyle S^{*}=\{(o_{i},o_{j})\mid o_{i}\in X_{k_{1}},o_{j}\in X_{k_{2}},o_{i}\in Y_{l_{1}},o_{j}\in Y_{l_{2}}\}} c = | S ∗ | {\displaystyle c=|S^{*}|} S ∗ = { ( o i , o j ) ∣ o i , o j ∈ X k , o i ∈ Y l 1 , o j ∈ Y l 2 } {\displaystyle S^{*}=\{(o_{i},o_{j})\mid o_{i},o_{j}\in X_{k},o_{i}\in Y_{l_{1}},o_{j}\in Y_{l_{2}}\}} d = | S ∗ | {\displaystyle d=|S^{*}|} S ∗ = { ( o i , o j ) ∣ o i ∈ X k 1 , o j ∈ X k 2 , o i , o j ∈ Y l } {\displaystyle S^{*}=\{(o_{i},o_{j})\mid o_{i}\in X_{k_{1}},o_{j}\in X_{k_{2}},o_{i},o_{j}\in Y_{l}\}} (任意の 1 ≤ i , j ≤ n , i ≠ j , 1 ≤ k , k 1 , k 2 ≤ r , k 1 ≠ k 2 , 1 ≤ l , l 1 , l 2 ≤ s , l 1 ≠ l 2 {\displaystyle 1\leq i,j\leq n,i\neq j,1\leq k,k_{1},k_{2}\leq r,k_{1}\neq k_{2},1\leq l,l_{1},l_{2}\leq s,l_{1}\neq l_{2}}
ランドインデックスは、 S {\displaystyle S} o i {\displaystyle o_{i}} o j {\displaystyle o_{j}} X {\displaystyle X} Y {\displaystyle Y} o i {\displaystyle o_{i}} o j {\displaystyle o_{j}} X {\displaystyle X} Y {\displaystyle Y}
その設定では、 a {\displaystyle a} b {\displaystyle b}
調整ランド指数は、ランド指数を偶然性に基づいて補正したものである[ 1] [ 2] [ 3]
しかし、順列モデルの前提は頻繁に破られる。多くのクラスタリングのシナリオでは、クラスターの数またはクラスターのサイズ分布が大幅に異なる。例えば、K平均法 では、クラスターの数は実務者によって固定されているが、それらのクラスターのサイズはデータから推測されるものとする。調整ランド指数のバリエーションは、ランダムなクラスタリングのさまざまなモデルを説明する[ 4]
ランド指数は0から1の間の値しか得られないが、調整ランド指数は、当てはまりが期待値よりも悪い場合、負の値を取り得る[ 5]
n {\displaystyle n} S {\displaystyle S} X = { X 1 , X 2 , … , X r } {\displaystyle X=\{X_{1},X_{2},\ldots ,X_{r}\}} Y = { Y 1 , Y 2 , … , Y s } {\displaystyle Y=\{Y_{1},Y_{2},\ldots ,Y_{s}\}}
X {\displaystyle X} Y {\displaystyle Y} [ n i j ] {\displaystyle \left[n_{ij}\right]} n i j {\displaystyle n_{ij}} X i {\displaystyle X_{i}} Y j {\displaystyle Y_{j}} n i j = | X i ∩ Y j | {\displaystyle n_{ij}=|X_{i}\cap Y_{j}|}
X ╲ Y Y 1 Y 2 ⋯ Y s sums X 1 n 11 n 12 ⋯ n 1 s a 1 X 2 n 21 n 22 ⋯ n 2 s a 2 ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ X r n r 1 n r 2 ⋯ n r s a r sums b 1 b 2 ⋯ b s {\displaystyle {\begin{array}{c|cccc|c}{{} \atop X}\!\diagdown \!^{Y}&Y_{1}&Y_{2}&\cdots &Y_{s}&{\text{sums}}\\\hline X_{1}&n_{11}&n_{12}&\cdots &n_{1s}&a_{1}\\X_{2}&n_{21}&n_{22}&\cdots &n_{2s}&a_{2}\\\vdots &\vdots &\vdots &\ddots &\vdots &\vdots \\X_{r}&n_{r1}&n_{r2}&\cdots &n_{rs}&a_{r}\\\hline {\text{sums}}&b_{1}&b_{2}&\cdots &b_{s}&\end{array}}}
順列モデルを使用したオリジナルの調整ランド指数は
A R I = ∑ i j ( n i j 2 ) − [ ∑ i ( a i 2 ) ∑ j ( b j 2 ) ] / ( n 2 ) 1 2 [ ∑ i ( a i 2 ) + ∑ j ( b j 2 ) ] − [ ∑ i ( a i 2 ) ∑ j ( b j 2 ) ] / ( n 2 ) {\displaystyle ARI={\frac {\left.\sum _{ij}{\binom {n_{ij}}{2}}-\left[\sum _{i}{\binom {a_{i}}{2}}\sum _{j}{\binom {b_{j}}{2}}\right]\right/{\binom {n}{2}}}{\left.{\frac {1}{2}}\left[\sum _{i}{\binom {a_{i}}{2}}+\sum _{j}{\binom {b_{j}}{2}}\right]-\left[\sum _{i}{\binom {a_{i}}{2}}\sum _{j}{\binom {b_{j}}{2}}\right]\right/{\binom {n}{2}}}}} ここで、 n i j , a i , b j {\displaystyle n_{ij},a_{i},b_{j}}
^ a b c W. M. Rand (1971). “Objective criteria for the evaluation of clustering methods”. Journal of the American Statistical Association (American Statistical Association) 66 (336): 846–850. doi:10.2307/2284239. JSTOR 2284239. ^ a b Lawrence Hubert and Phipps Arabie (1985). “Comparing partitions”. Journal of Classification 2 (1): 193–218. doi:10.1007/BF01908075. ^ Nguyen Xuan Vinh, Julien Epps and James Bailey (2009). "Information Theoretic Measures for Clustering Comparison: Is a Correction for Chance Necessary?" (PDF) . ICML '09: Proceedings of the 26th Annual International Conference on Machine Learning . ACM. pp. 1073–1080. ^ Alexander J Gates and Yong-Yeol Ahn (2017). “The Impact of Random Models on Clustering Similarity”. Journal of Machine Learning Research 18 : 1-28. http://www.jmlr.org/papers/volume18/17-039/17-039.pdf . ^ Silke Wagner (2007年1月12日). “Comparing Clusterings - An Overview” (pdf). 2021年10月5日 閲覧。
MATLAB mexファイルを使用した C++ の実装 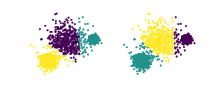




































![{\displaystyle \left[n_{ij}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cf6d61cf9a2d775ae845160965e9e62ca6e038d3)





![{\displaystyle ARI={\frac {\left.\sum _{ij}{\binom {n_{ij}}{2}}-\left[\sum _{i}{\binom {a_{i}}{2}}\sum _{j}{\binom {b_{j}}{2}}\right]\right/{\binom {n}{2}}}{\left.{\frac {1}{2}}\left[\sum _{i}{\binom {a_{i}}{2}}+\sum _{j}{\binom {b_{j}}{2}}\right]-\left[\sum _{i}{\binom {a_{i}}{2}}\sum _{j}{\binom {b_{j}}{2}}\right]\right/{\binom {n}{2}}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9e0f6f21c547bd71629352a4b543119f6822d7ad)






